Quantified Self Meets IDE: A Year of Data
by Matt CholickMore than a year ago, I started tracking exactly what code I was working on using WakaTime. As I've moved from specialized to more generalized as a developer, I wanted some real data to know where I'm focusing; data I could use to drive decisions. Am I getting a picture of the full stack? Was our team too focused on operations this sprint? Am I learning what I want to be learning?
The Data
Now that I have a solid year's worth of data, some analysis is in order. The question I want to explore today is "How does that time spend coding breakdown by language?" We do mostly pair programming, so the actual numbers I've captured aren't accurate, but I believe the percentages are. WakaTime hooks into Sublime, Visual Studio, and the JetBrains tools, so it captures nearly all my source edits. It likely does underrepresent operational work, as it has no hooks into terminal. I've only put it on my work machine (that's what I was interested in measuring), so side projects aren't in the mix. One final thing to note is that the data included 8% of my time bucketed into "other", which was a grab bag of scratch buffers in various technologies, config files, and other random things. Anyway, here's a year of data broken down by language:
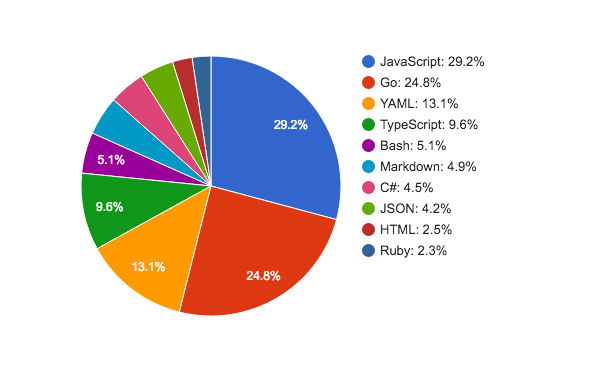
Several couple things jump out for me:
- 18% infrastructure
- Though operations work in general is underrepresented, infrastructure as code isn't. All the Bash and YAML (Ansible and Bosh) fall in this bucket. So, I've spent ~18% of my time coding up our infrastructure.
- 12% front-end
- The division between TypeScript and JavaScript is useful, because for historical reasons the UI is TypeScript while JavaScript represents server side Node.js code. So, toss in the HTML and that comes to ~12% front-end work.
- 60% back-end
- Add up the JavaScript, Go, and C# to arrive at ~60% back-end work.
- 5% documentation
- Markdown is either documentation, notes, or knowledge base articles. It's a higher percentage than I would have guessed.
- 4% data
- ~4% JSON is pretty interesting, in that this is time just spent looking at data. There's a little bit of config files in the mix there, but when I looked over the data, it was basically time spent studying API requests and responses.
- 2% reading oss
- Ruby is an outlier, as I don't actually write Ruby code. This fraction of my time was studying the underlying open source software to figure out exactly how or why it's behaving a particular way. This wasn't even in an effort to change things, just reason about the platform we're building upon.
I have buzzword aversion to the terms "full-stack" or "devops", so I'm just going to call our team a collection of generalists. But, at least for this sample size of n=1, the graph is concretely what it looks like being a generalist working with in a team of other generalists.
Thoughts
I've spent quite a bit of time now both in specialist and generalist roles. One thing I really like with my current model, where each team members works with all the technology, is that folks have the understanding and mandate to solve problems anywhere. When very specialized, I've been frustrated at times not being able to solve issues outside my area. I actually wrote a little on this five years ago when I was much more specialized:
...to gain some experience. I'm a web developer, but at our shop we're very specialized. The developer's don't deal with server maintenance much. This specialization allows groups to be more productive, but it also makes troubleshooting issues on the border between the application and the server (class loading issues, for example) more difficult to deal with. It's frustrating not having the experience to deal with these kinds of issues.
My team, down to the individual, is empowered and expected to solve problems and improve all aspects of our product. That's a powerful concept.
I also think incentives are well aligned working this way. "You build it, you run it" means that we're on call, so we do spend the time to build monitoring and automation; one can see it above as I spent 1/5 of my coding time on automating infrastructure. I have been pulled from sleep in the middle of the night by my software, and it really does change one's perspective. Delivering something reliable becomes more important. There's a very real moral hazard when reliability is divorced from feature delivery.
This applies to other areas as well. We're also both building and consuming our APIs, so we strike a balance between pragmatism and hardcore HATEOAS. When our customers are confused and generate support tickets, we have the incentive to write up examples and improve the user experience. There's neither handoff, nor transition, nor gaps.
There are disadvantages to generalization as well. The 10,000 hour rule isn't actually a thing (the original source for the number in Outliers, in fact, wrote an amusingly titled rebuttal "The Danger of Delegating Education to Journalists"), but it is convenient shorthand for a lot of time invested in something. I've spent that many hours and more working on the JVM.
In contrast, looking at the graph above, I've spent my more recent time spread across many languages and even more frameworks. Despite not really touching Java or Groovy for the past year and a half, it still can feel more familiar then Go or TypeScript. Never focusing long enough to gain real expertise, I sometimes find myself googling the most fundamental bits of language syntax. What isn't visible in the graph above are the context switches. We might go multiple sprints without touching any Node.js or Go code. With these switches, I'll forget how to receive on a Go channel or Typescript's delimiting character for multiline strings.
Another disadvantage is making decisions about technologies and frameworks in an absence of deep expertise. Choosing among upstart/monit/runit/systemd/daemonize is a recent concrete example. This is the sort of choice someone with years of Linux system administration experience would have a very informed opinion.
Sadly, I don't have a satisfying conclusion to this post. Some days, I miss that deep expertise and language facility that comes from working with the same language and framework for months on end: to know a thing fully. On the other hand, I really do love that I can build, maintain, monitor, update, and deploy full solutions with confidence.